String Matching with BERT, TF-IDF, and more!
As a data scientist, you might be faced with tabular data that has at least one text-based column. Whether they are names, addresses, or company names, in my experience, these almost always need to be cleaned as they are often filled by people and therefore highly prone to errors.
This is where Fuzzy String Matching comes in. It is a collection of techniques that are used to find the best match between two sets of strings. Although there are many algorithms available, I could not for the life of me find a solution that integrates many of these algorithms.

Thus, I set out to create a solution that allows you to quickly use common string matching techniques whilst still giving you the ability to customize and easily add models.
Hereby, I introduce to you PolyFuzz. PolyFuzz performs fuzzy string matching, string grouping, and contains extensive evaluation functions. PolyFuzz is meant to bring fuzzy string matching techniques together within a single framework.
Currently, methods include a variety of edit distance measures, a character-based n-gram TF-IDF, word embedding techniques such as FastText and GloVe, and 🤗 transformers embeddings.
In this article, I will go through the basics of PolyFuzz and guide you towards more complex applications such as creating and customizing models for your own purposes.
You can find the GitHub repository of PolyFuzz here.
1. Installation
You can install PolyFuzz via pip:
pip install polyfuzz
This will install the base dependencies. If you want to speed up the cosine similarity comparison and decrease memory usage, you can use sparse_dot_topn which is installed via:
pip install polyfuzz[fast]
If you want to be making use of 🤗 Transformers, install the additional Flairdependency:
pip install polyfuzz[flair]
To install all the additional dependencies:
pip install polyfuzz[all]
2. Quick Start
We start by defining two lists of strings, one list that we would like to map from, or correct, and one list to map to.
Here, we are going to use the following two small lists:
from_list = ["apple", "apples", "appl", "recal", "house", "similarity"]
to_list = ["apple", "apples", "mouse"]
Next, we want to compare the similarity of strings by using Levenshtein edit distance. It is a technique commonly used for comparing strings and calculates the number of changes one has to make to go from one string to another.
To do this, we only have to instantiate PolyFuzz and specify EditDistance:
from polyfuzz import PolyFuzz
model = PolyFuzz("EditDistance")
model.match(from_list, to_list)
The resulting matches can be accessed through model.get_matches():
>>> model.get_matches()
From To Similarity
0 apple apple 1.00
1 apples apples 1.00
2 appl apples 0.90
3 recal apple 0.40
4 house mouse 0.80
5 similarity apple 0.18
The similarity column indicates how similar strings are to each other. The implemented models make sure to normalize the score between 0 and 1 such that is easier to evaluate the results.
Group Matches
At times, the strings that you matched to may not be standardized and could need some cleaning. In our example, we find in our To column both the strings apple and apples. Personally, I would like to have seen those words grouped together.
And, surprise, we are going to do this in PolyFuzz!
First, we extract the similarity between strings by calculating the edit distance. Then, we apply Single Linkage to group strings that are most similar to each other by continuously adding similar strings to a group that passes a certain threshold.
When we group and extract the new matches, we can see an additional column Group in which all the To matches were grouped to:
>>> model.group("EditDistance")
>>> model.get_matches()
From To Similarity Group
0 apple apple 1.00 apples
1 apples apples 1.00 apples
2 appl apples 0.90 apples
3 recal apple 0.40 apples
4 house mouse 0.80 apples
5 similarity apple 0.18 apples
As can be seen above, it looks like we have grouped apple and apples together. To inspect the clusters, we simply run the following:
>>> model.get_clusters()
{0: ['apples', 'apple']}
As you can see, apple and apples were merged together into group 0.
Precision-Recall Curve
There is a lot of tweaking involved when deciding which match is “correct”. You could set the similarity to be at least 0.95 but then you lose a lot of matches that might have been correct!
To visualize this trade-off between accuracy and number of matches, we can express our results as precision and recall respectively.
Precision is here defined as the minimum similarity score before a match is correct and recall the percentage of matches found at a certain minimum similarity score.
Creating the visualizations is as simple as:
model.visualize_precision_recall()

The resulting Precision-Recall curve tells us how the trade-off between the minimum similarity and percentage matched looks like.
You can expect a much smoother curve if we throw more data at PolyFuzz.
3. Models
Currently, the following models are implemented in PolyFuzz:
-
RapidFuzz
-
EditDistance (you can use any distance measure, see documentation here)
-
TF-IDF
-
FastText and GloVe
-
🤗 Transformers
RapidFuzz
The most often used technique for calculating the edit distance between strings is Levenshtein. Although FuzzyWuzzy is one of the most commonly used implementations of Levenshtein, it has a GPL2 license which can be a bit restrictive in some cases.
Fortunately, there is a faster version out there with an MIT license, namely RapidFuzz which is quickly accessible in PolyFuzz:
from polyfuzz import PolyFuzz
from polyfuzz.models import RapidFuzz
matcher = RapidFuzz(n_jobs=1, score_cutoff=0.8)
model = PolyFuzz(matcher)
model.match(from_list, to_list)
As you can see, we simply call RapidFuzz from polyfuzz.models and pass it through a PolyFuzz instance. You can specify the number of jobs and the minimum score at which it searches for a match.
Edit Distance
Although RapidFuzz is a nice implementation, what if you want to use any other edit distance algorithm? There are plenty of use-cases where Levenshtein might not be the answer.
For those cases, PolyFuzz allows you to use the EditDistance model from polyfuzz.models to pass in any distance function. As long as that distance function takes in two strings and spits out a float, you can pass anything!
In the example below, we are going to be using Jaro Winkler Similarity from the jellyfish package to create our custom scorer:
from polyfuzz import PolyFuzz
from polyfuzz.models import EditDistance
from jellyfish import jaro_winkler_similarity
jellyfish_matcher = EditDistance(scorer=jaro_winkler_similarity)
model = PolyFuzz(jellyfish_matcher)
model.match(from_list, to_list)
There is an abundance of edit distance algorithms out there that you might want to be using. This way, you can easily add any edit distance algorithm to PolyFuzz.
TF-IDF
A nifty trick for calculating the similarity between two strings is by applying TF-IDF not on the entire words, but on character n-grams to create vector representations. Then, we can use cosine similarity to calculate how similar strings are to each other and extract the best match!
As always, simply import TF-IDF from polyfuzz.models and pass it through your PolyFuzz instance:
from polyfuzz.models import TFIDF
from polyfuzz import PolyFuzz
tfidf = TFIDF(n_gram_range=(3, 3))
model = PolyFuzz(tfidf)
model.match(from_list, to_list)
You can specify n_gram_range with any two values, but it is advised to start off with (3, 3) and explore from there.
Embeddings
With Flair, we can use all 🤗 Transformers that are publicly available. We simply have to instantiate any Flair WordEmbedding method and pass it through PolyFuzzy. Then, we calculate the cosine similarity between the embeddings to extract the best match.
We need to import Embeddings from polyfuzz.models and import embeddings from the Flair package. Below, we are going to use BERT to embed the strings:
All models listed above can be found in polyfuzz.models and can be used to create and compare different models:
from polyfuzz import PolyFuzz
from polyfuzz.models import Embeddings
from flair.embeddings import TransformerWordEmbeddings
embeddings = TransformerWordEmbeddings('bert-base-multilingual-cased')
bert = Embeddings(bert)
models = PolyFuzz(bert)
model.match(from_list, to_list)
You can use any of the WordEmbedding techniques implemented in Flair, such as FastText, GloVe, BERT, etc.
Multiple Models
One great feature of PolyFuzz is the ability to match, group, and visualize multiple models within a single PolyFuzz instance. This allows you to quickly compare models and decide for yourself which, or which combination, you are going to use.
In the example below, we will be comparing FastText, TF-IDF, and RapidFuzz with each other:
from polyfuzz import PolyFuzz
from polyfuzz.models import Embeddings, TFIDF, RapidFuzz
from flair.embeddings import WordEmbeddings
fasttext_embeddings = WordEmbeddings('en-crawl')
fasttext = Embeddings(fasttext_embeddings, min_similarity=0, model_id="FastText")
tfidf = TFIDF(min_similarity=0, model_id="TF-IDF")
rapidfuzz = RapidFuzz(n_jobs=-1, score_cutoff=0, model_id="RapidFuzz")
matchers = [tfidf, fasttext, rapidfuzz]
model = PolyFuzz(matchers)
model.match(from_list, to_list)
model.visualize_precision_recall(kde=True)
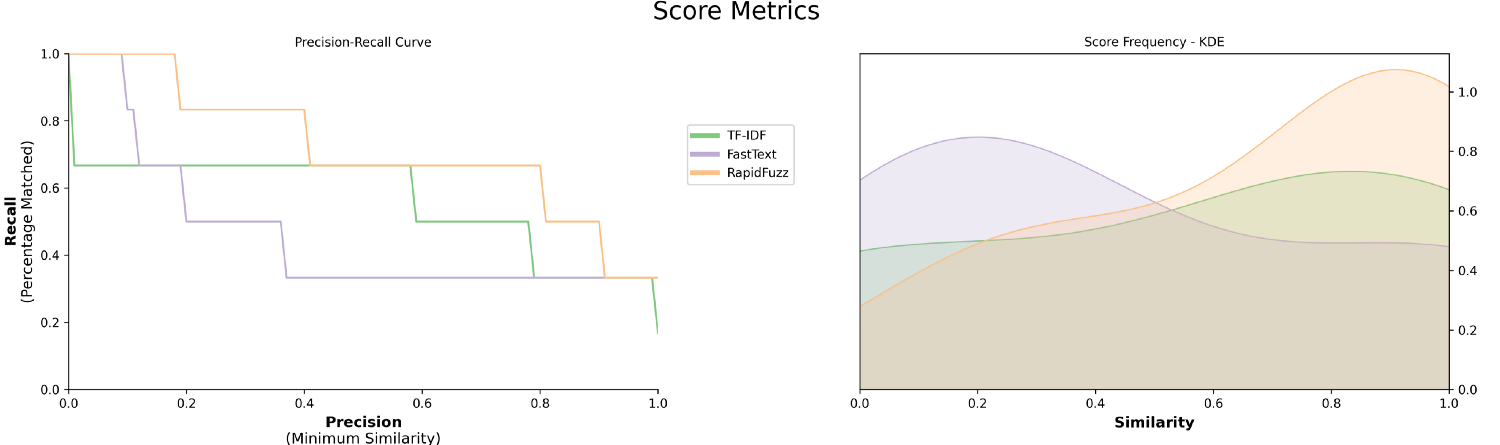
With the added KDE plot we can clearly see the distribution of similarity scores and compare performances across models.
4. Customization
Customization is a big part of PolyFuzz. When you want to calculate string similarity then there are many algorithms to choose from and new ones are frequently created.
Since not all of them can realistically be implemented, PolyFuzz allows you to create any custom matcher. If you follow the structure of PolyFuzz’s BaseMatcher you can quickly implement any model you would like.
Below, we are implementing the ratio similarity measure from RapidFuzz.
import numpy as np
import pandas as pd
from rapidfuzz import fuzz
from polyfuzz.models import BaseMatcher
class MyModel(BaseMatcher):
def match(self, from_list, to_list):
# Calculate distances
matches = [[fuzz.ratio(from_string, to_string) / 100 for to_string in to_list]
for from_string in from_list]
# Get best matches
mappings = [to_list[index] for index in np.argmax(matches, axis=1)]
scores = np.max(matches, axis=1)
# Prepare dataframe
matches = pd.DataFrame({'From': from_list,'To': mappings, 'Similarity': scores})
return matches
custom_model = MyModel()
model = PolyFuzz(custom_model)
model.match(from_list, to_list)
As you might have noticed, MyModel only needs to have a match function in order to be used within PolyFuzz. Then, match has two lists as input and needs to output a dataframe with the columns From, To, and Similarity.
And that is it! You can create whatever string similarity algorithm you might think of and easily compare with other models and visualize the results.